Sunday, 20 August 2023
This week in AI: Amazon ‘enhances’ reviews with AI while Snap’s goes rogue
by Earn Media
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of the last week’s stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week in AI, Amazon announced that it’ll begin tapping generative AI to “enhance” product reviews. Once it rolls out, the feature will provide a short paragraph of text on the product detail page that highlights the product capabilities and customer sentiment mentioned across the reviews.
Sounds like a useful feature, no? Perhaps for shoppers and sellers. But what about reviewers?
I’m not going to make the case that Amazon reviews are a form of high art. On the contrary, a fair number on the platform aren’t real — or are AI-generated themselves.
But some reviewers, whether out of genuine concern for their fellow shopper or an effort to get the creative juices flowing, put time into crafting reviews that not only inform, but entertain. Summaries of these reviews would do them an injustice — and miss the point entirely.
Perhaps you’ve stumbled upon these gems. Often, they’re found in the review sections for books and movies, where, in my anecdotal experience, Amazon reviewers tend to be more… verbose.
Image Credits: Amazon
Take Amazon user “Sweet Home’s” review of J. D. Salinger’s “Catcher in the Rye,” which clocks in at over 2,000 words. Referencing the works of William S. Burroughs and Jack Kerouac as well as George Bernard Shaw, Gary Snyder and Dorothy Parker, Sweet Home’s review is less a review than a thorough analysis, picking at and contextualizing the novel’s threads in an attempt to explain its staying power.
And then there’s Bryan Desmond’s review of “Gravity’s Rainbow,” the infamously dense Thomas Pynchon novel. Similarly wordy — 1,120 words — it not only underlines the book’s highlights (dazzling prose) and lowlights (outdated attitudes, particularly toward women), as one would expect from a review, but relays in great detail Desmond’s experience of reading it.
Could AI summarize those? Sure. But at the expense of nuance and insight.
Of course, Amazon doesn’t intend to hide reviews from view in favor of AI-generated summaries. But I fear that reviewers will be less inclined to spend nearly as much time and attention if their work goes increasingly unread by the average shopper. It’s a grand experiment, and I suppose — as with most of what generative AI touches — only time will tell.
Here are some other AI stories of note from the past few days:
- My AI goes rogue: Snapchat’s My AI feature, an in-app AI chatbot launched earlier this year with its fair share of controversy, briefly appeared to have a mind of its own. On Tuesday, the AI posted its own Story to the app and then stopped responding to users’ messages, which some Snapchat users found disconcerting. Snapchat parent company Snap later confirmed it was a bug.
- OpenAI proposes new moderation technique: OpenAI claims that it’s developed a way to use GPT-4, its flagship generative AI model, for content moderation — lightening the burden on human teams.
- OpenAI acquires a company: In more OpenAI news, the AI startup acquired Global Illumination, a New York–based startup leveraging AI to build creative tools, infrastructure and digital experiences. It’s OpenAI’s first public acquisition in its roughly seven-year history.
- A new LLM training dataset: The Allen Institute for AI has released a huge text dataset for large language models (LLMs) along the lines of OpenAI’s ChatGPT that’s free to use an open for inspection. Dolma, as the dataset is called, is intended to be the basis for the research group’s planned open language model, or OLMo (Dolma is short for “Data to feed OLMo’s Appetite).
- Dishwashing, door-opening robots: Researchers at ETH Zurich have developed a method to teach robots to perform tasks like opening and walking through doors — and more. The team says the system can be adapted for different form factors, but for the sake of simplicity, they executed demos on a quadruped — which can be viewed here.
- Opera gets an AI assistant: Opera’s web browser app for iOS is getting an AI assistant. The company announced this week that Opera on iOS will now include Aria, its browser AI product built in collaboration with OpenAI, integrated directly into the web browser, and free for all users.
- Google embraces AI summaries: Google this week rolled out a few new updates to its nearly three-month-old Search Generative Experience (SGE), the company’s AI-powered conversational mode in Search, with a goal of helping users better learn and make sense of the information they discover on the web. The features include tools to see definitions of unfamiliar terms, those that help to improve your understanding and coding information across languages and an interesting feature that lets you tap into the AI power of SGE while you’re browsing.
- Google Photos gains AI: Google Photos added a new way to relive and share your most memorable moments with the introduction of a new Memories view, which lets you save your favorite memories or create your own from scratch. With Memories, you can build out a scrapbook-like timeline that includes things like your most memorable trips, celebrations and daily moments with loved ones.
- Anthropic raises more cash: Anthropic, an AI startup co-founded by former OpenAI leaders, will receive $100 million in funding from one of the biggest mobile carriers in South Korea, SK Telecom, the telco company announced on Sunday. The funding news comes three months after Anthropic raised $450 million in its Series C funding round led by Spark Capital in May.
More machine learnings
I (that is, thine co-author Devin) was at SIGGRAPH this last week, where AI, despite being a bogeyman in the film and TV industry right now, was in full force as both a tool and research subject. I’ll have a longer story soon about how it’s being used by VFX artists in innovative and totally uncontroversial ways soon, but the papers on display were also pretty great. This session in particular had several interesting new ideas.

Image Credits: Tel Aviv University
Image generating models have this weird thing where if you tell them to draw “a white cat and a black dog,” it often mixes the two up, ignores one, or makes a catdog or animals that are both black and white. An approach from Tel Aviv University called “attend and excite” sorts the prompt into its constituent pieces through attention, and then makes sure the resulting image contains proper representations of each. The result is a model much better at parsing multi-subject prompts. I’d expect to see something like this integrated into art generators soon!
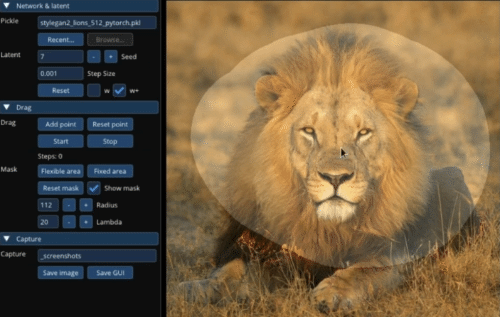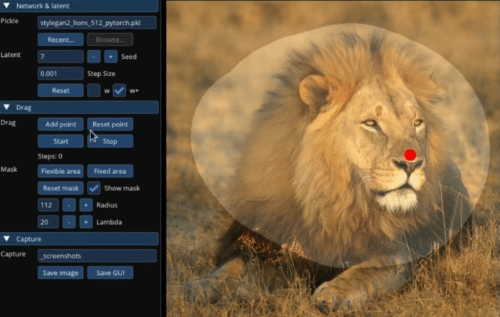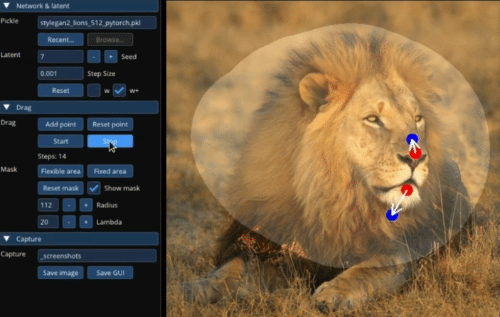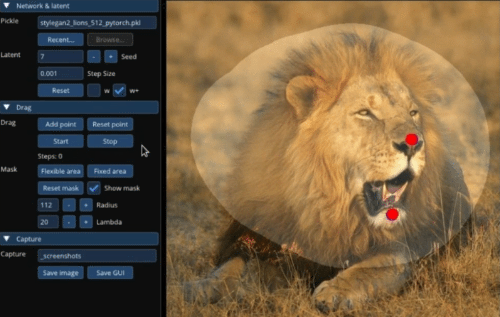
Image Credits: MIT/Max Planck Institute
Another weakness of generative art models is that if you want to make small changes, like the subject looking a little more to the side, you have to redo the whole thing — sometimes losing what you liked about the image to begin with. “Drag Your GAN” is a pretty astonishing tool that lets the user set and move points one by one or several at a time – as you can see in the image, a lion’s head can be turned, or its mouth opened, by regenerating just that portion of the image to accord with the new proportions. Google is in the author list so you can bet they’re looking at how to use this.

Image Credits: Tel Aviv University
This “semantic typography” paper is more fun, but also extremely clever. By treating each letter as a vector image and nudging that image towards a vector image of the object a word refers to, it creates pretty impressive logotypes. If you’re stuck on how to turn your company name into a visual pun, this could be a great way to get started.
Elsewhere, we have some interesting cross-pollination between brain science and AI.
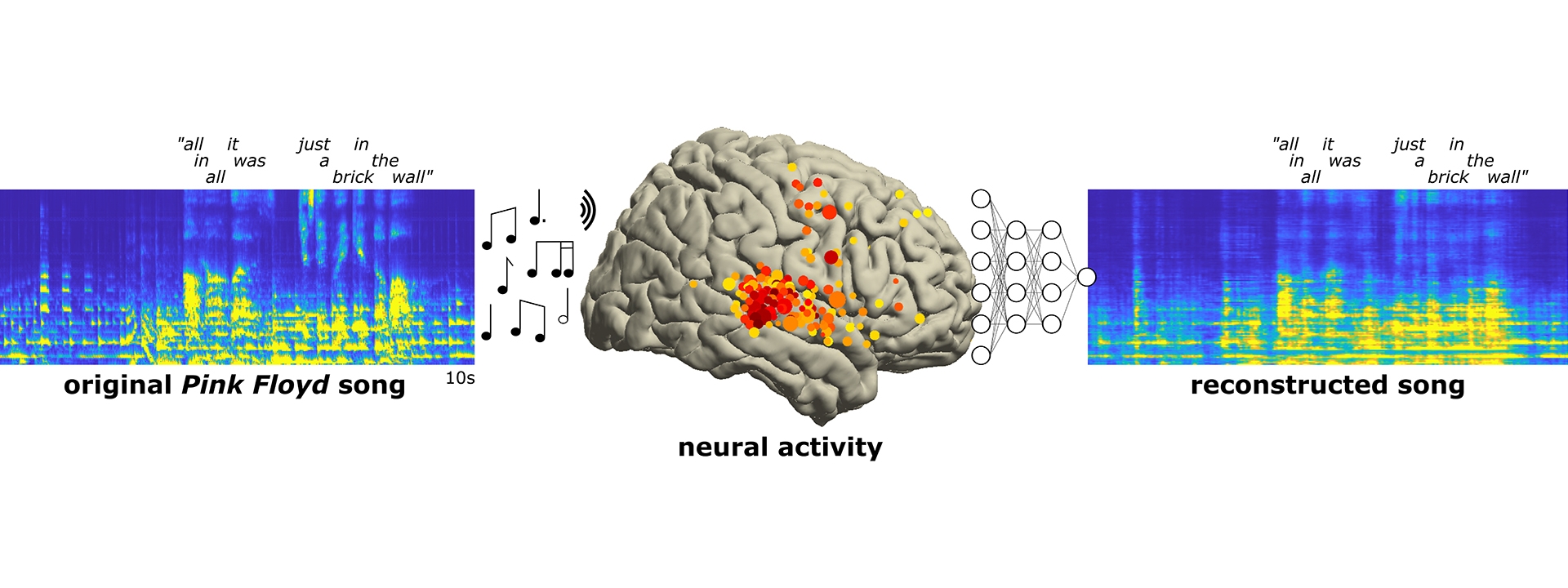
Well, it’s not quite this simple.
These Berkeley researchers used a machine learning model to interpret brain activity while listening to music, and reconstruct some of the clusters that were focused on rhythm, melody, or vocals. I’m always skeptical of this kind of “we read the brain” type studies, so take it all with a grain of salt, but ML is great at isolating a signal in noise, and brain activity is very, very noisy.
MIT and Harvard teamed up to try to advance our understanding of astrocytes, cells in the brain that perform some as-yet-unknown function. They propose that the cells may act as something like a transformer or attention mechanism – a machine learning concept being mapped onto the brain rather than vice versa! Senior paper author Dmitry Krotov from MIT sums it up well:
The brain is far superior to even the best artificial neural networks that we have developed, but we don’t really know exactly how the brain works. There is scientific value in thinking about connections between biological hardware and large-scale artificial intelligence networks. This is neuroscience for AI and AI for neuroscience.
In medical AI, data from consumer devices is often considered noisy as well, or unreliable. But again, ML systems can adapt, as this new paper from Yale shows. The research should move us closer to wearables that warn us of heart-related issues before they become acute.

Students demonstrate their empty chair finding app.
One of GPT-4’s first practical applications was use in Be My Eyes, an app that helps blind folks navigate with the help of a remote partner. EPFL students developed two more apps that could be pretty nice for anyone with a visual impairment. One simply directs the user towards an empty seat in a room, and the other reads off only the relevant info from medicine bottles: the active ingredient, dosage, etc. Such simple but necessary tasks!
Lastly we have the toddler-equivalent “RoboAgent” developed by CMU and Meta, which aims to learn everyday skills like picking things up or understanding object interactions just by looking and touching things — the way a child does.
“An agent capable of this sort of learning moves us closer to a general robot that can complete a variety of tasks in diverse unseen settings and continually evolve as it gathers more experiences,” said CMU’s Shubham Tulsiani. You can learn more about the project below:
